Using Tailscale for home server
For those of you who are new to my blog, I had written about my home server setup (hydra) a few months back. Since then I’ve tweaked the setup a bit and made some changes to how I organise/deploy applications inside my cluster. I’ll be talking about the updates made so far and the reason behind them.
A brief overview of what has changed from hydra v0.1 to hydra v0.2:
-
Replaced Wireguard with Tailscale
-
Added a new worker node (residing in DigitalOcean, Bengaluru) to the existing RPi k3s cluster.
-
Shifted from PiHole to Adguard DNS upstreaming to Unbound.
-
Containerised all workloads and deployed on K8s (using
k3splatform).
The setup looks something like this now:
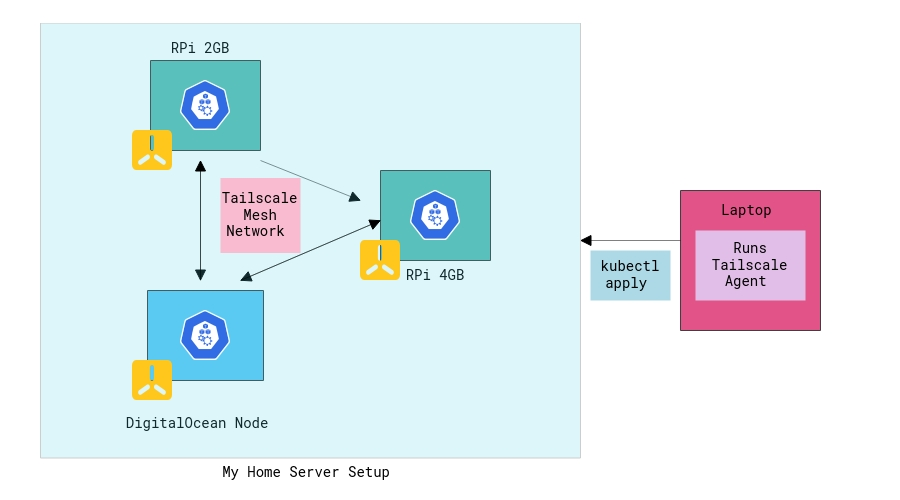
Let’s take a quick look at some of the above things in detail!
Using Tailscale#
So, before we jump to why I started using Tailscale, let’s address a few things about Wireguard which bothered me.
-
Adding new devices is a real PITA and quite often laziness kicks in to generate a QR code or Private/Public key pair. So, for those of you unaware, Wireguard needs a client config to add the server endpoint and it’s public key for the client to communicate with the server. You need to add the client’s private key on the server-side as well for the exchange of encrypted packets to happen. Doing all of this manually has been one of the reasons I’ve not added/updated my devices as regularly as I’d like to do. For eg, on my recently bought iPad, I just haven’t bothered to do all of this, cause ugh I am lazy?
-
Having a central VPN server to talk to my RPi from my local network just doesn’t seem right you know? Especially when both devices are literally lying in the same room, sending the packets to a server somewhere in Electronic City (DO, blr region) from JP Nagar (where I live) feels like totally unnecessary. I really needed a mesh network to reduce wasted bandwidth and latencies. Having a central VPN server is also a SPOF, not that my home-server runs any mission-critical workloads, but still good to avoid where we can. Where else can I flex my ops-chops skills if not my home server, eh?
I started looking at different mesh VPN setups and Tailscale attracted me the most. I heard about Tailscale first time when I saw bradfitz’s post about leaving Google and joining Tailscale on HN. Interestingly, Tailscale is built on top of wireguard-go (the userspace implementation of Wireguard kernel module). Since I was already familiar with Wireguard and had been using it for almost a year, I got curious on Tailscale.
Tailscale basically sets up a point-to-point encrypted network across all your devices. What that means is there’s no “relay” (like Wireguard server) and clients can talk to each other directly. While it may seem that it is easy to set this up with a bunch of shell scripting-foo (just add all Wireguard peers in each peer config), Tailscale attempts to do a lot of the heavy lifting by making the network seamless and handling authentication.
Coordination Server#
So, when we add a new device to Wireguard server, we basically need to generate a private/public key pair as explained above. When you’re setting up Tailscale agent, it does all of this in the background and asks you to authorise to a central co-ordination server. Now, this server is only used to exchange information about each peer in your network. The tailscale agent uploads the private/public key information of the peer you are currently on and any time any new peer joins the network, all of the agents’ configurations are updated real-time. The coordination server periodically checks for any new changes and pushes the updates to the agent on each node.
The real juice is that they authenticate via OAuth, OIDC or SAML. Which means that you can use your existing 2FA configurations to authenticate a new node in the network. However, this might be a point of concern for some users, but I chose convenience here. Also, since the traffic flows through the nodes directly, and is encrypted there’s not much to worry here. I’ve been following Tailscale closely and they do plan to opensource the co-ordination server in future, so maybe when that happens I’ll self-host it.
NAT Traversal#
Apart from handling the auth, Tailscale does a pretty good job at handling connectivity across different network topologies. So, basically, if you want to peer 2 devices over the public internet you’d need to perform NAT Traversal. There are several NAT hole punching techniques which allow traversing NAT but since they are not standardised and sometimes due to erratic NAT behaviour, it poses quite a challenge to do it seamlessly. And, I’m not even talking about roaming networks as of yet.
Tailscale agents can perform NAT traversal using ICE and STUN. What all of this practically means is if you’re sitting in a cafe somewhere and you want to access any of your internal service it is possible without messing around any firewall ports :D
TL;DR: I decided to give Tailscale a shot and was quite impressed by how easy it was to setup. You can refer to the official docs for more instructions but I was able to set it up across 2 RPis and have them talk to each other under 15 minutes. I think that’s quite an awesome feat in itself. The only sad bit is they don’t have an Android app yet, so I am eagerly waiting for it.
Hybrid K3s Cluster#
So, I am running a k3s cluster on my RPi. At that time I was still using DO for running Pihole, Unbound, public DNSCrypt resolver etc. I decided to standardise the ad-hoc deployments to manage them efficiently. It also allowed me to play around with more on K8s which was my original goal behind buying these Pi was.
Now, I’ve 2*RPi nodes, the k8s master node runs on the 4GB RPi while the 2GB variant serves as a worker node. I decided to get a bit fancy with my setup and hooked up the k3s agent installation script on a DO node andta-da! I have a multi-arch(amd64 and arm64), hybrid (bare metal and cloud) K8s cluster ready! I think if I sprinkle some ML/AI + Bitcoins in the above setup, I’m all set to raise VC funding for hydra.
I wanted to learn Terraform as part of my work at my org as well, so I created + managed the entire droplet through terraform. The script has modules to provision a droplet, attach an elastic IP, configure firewall rules and add my SSH key to the server. Quite easy to manage and I am generally a hater of GUIs, so Terraform is indeed a blessing in disguise.
I know some of my opinions are a bit strong but don’t worry I get meme’d/burnt for this almost every day by my work colleagues.
Pihole to Adguard#
While Pihole works really well for blocking Ads it had some features lacking, particularly DOT and DOH support out of the box. I decided I’ll shift to Adguard as the codebase is in Go - something which I am a bit familiar with and also the UI feels a bit sleek and refreshing too!
Accessing internal services#
A major challenge for me was however to configure access to internal services on the K8s cluster. Since I have bare metal worker nodes, it’s not possible to deploy a cloud load balancer. For now, I went with a really simple old school solution, to expose an Nginx proxy front-ending all my services through NodePort. I am planning to look at Traefik or Istio for this but I wanted to just shipit! at this point.
Here’s a very basic example of an nginx config for ip.mrkaran.dev that I run on my cluster:
server {
server_name ip.mrkaran.dev;
# reverse proxy
location / {
proxy_pass http://100.96.239.6:30506; # tailscale IP, connecting to NodePort service
include fluff/proxy.conf;
}
}30506 port is exposed by the Service object backing up the pods for that application. Since a NodePort service is available on any K8s node, you can give the Tailscale IP for any node and the routing will be handled by kube-proxy.
Challenges faced#
Mesh or mess#
Setting all of this up didn’t come without its own challenges or hurdles. Right off the bat, the first problem was that I was seeing really high latencies from my RPi node to DO node through Tailscale. Now, since both the nodes are physically in Bangalore and they are connecting to each other (or that’s what I had presumed), I didn’t expect latencies to be as high as 500-600ms. Bollocks!
Eventually, I’d figured thanks to my super restrictive rules on the firewall of DO node, I had blocked all inbound UDP connection. That means NAT hole punching through STUN is simply not possible. In such cases, Tailscale forwards all packets to an encrypted TURN server(called DERP - Designated Encrypted Relay for Packets), which basically are TCP encrypted relays. Tailscale manages this network of DERPs and the one I got connected to was somewhere in the USA.
Bottom line, I was all pumped up to talk to a DO node from my RPi node but as it turns out (no pun intended) my packets were flowing through the USA! Ah so bad. Anyway, opening up UDP from the Tailscale subnet, fixed the issue and latencies were back to being sub 10ms. Yay!
Overlay over an overlay#
Next up, were problems with K3s networking from the DO node to RPi node. The DO node was in a NotReady state because the agent couldn’t reach the server:
Apr 14 09:00:33 hydra-control k3s[19746]: I0414 09:00:33.306650 19746 log.go:172] http: TLS handshake error from 100.97.222.106:51516: read tcp 100.96.239.6:6443->100.97.222.106:51516: read: connection reset by peerThrough some trial and error and reading the docs, I figured that flannel is running as a CNI in k3s. Now the problem is flannel itself is an overlay network. But… Tailscale already is an overlay network (Wireguard) so the packets are not being routed correctly and being dropped halfway in the master node (I am guessing the DNAT/SNAT translation botched up here).
The trick was to just change flannel backend to run in the host namespace only. That solved the above issue for me.
However, I still had one more issue. The DO node’s public IP was being advertised, while the agent was running on Tailscale network interface so the master was never able to reach the agent. Similarly, when the agent tried to communicate with the server, the private IP of the node was being advertised.
Setting the --node-external-ip <tailscale-ip> in k3s config seemed to have fixed the problem.
Now all of the nodes in the cluster had proper Tailscale IPs advertised and the node went to Ready state, at last!
Who let the DNS out#
So, I’ve a chicken and egg problem in my setup. Since my laptop runs a Tailscale agent and whenever I boot up my systemm, Tailscale attempts to posts logs to log.tailsclae.io and fails to start if it cannot. The problem here is who resolves the DNS for me?
I run a local DNS server with CoreDNS forwarding my queries to Adguard. Now if I can’t reach Adguard (since Tailscale agent hasn’t initialised), how am I supposed to resolve log.tailscale.io? I did what any sane guy would do, write a simple hacky bash script:
#!/bin/bash
sudo chattr -i /etc/resolv.conf
sudo echo 'nameserver 1.1.1.1' > /etc/resolv.conf
echo "changed dns server to 1.1.1.1"
sudo tailscale up
sudo echo 'nameserver 127.0.0.1' > /etc/resolv.conf
echo "changed dns server back to 127.0.0.1"
sudo chattr +i /etc/resolv.confYes, it’s quite insane. Also, I’ve not been able to figure out how to stop NetworkManager from changing my /etc/resolv.conf so I rely on a hack (documented in Arch official docs), to lock the file so any process cannot modify it. Quirky, but works!
Storage#
Unfortunately, I don’t have any external HDD/SSD so I am postponing running any stateful workloads till I get one soon (whenever lockdown gets over in my area). I plan to deploy an NFS server so I can run stateful workloads across any node and have redundancy in form of cloud backups. I’ve also heard cool things about Longhorn but unfortunately, it doesn’t have ARM support.
Final Thoughts#
Well, I am quite stoked by my current setup right now. Learnt a bunch of cool things around NAT traversal, zero-trust networking, realised the old days of LAN were so much better (not that I am that old to have experienced, my first internet connection was rather broadband at home, not even dial-up). Tailscale opens up a lot of new opportunities for corporate VPNs and it is something definitely to watch out for as they continue improving the product.
Also, I was super elated when bradfitz himself had commented on my tweet, not gonna lie!
{{< tweet 1249552822674149376 >}}
Credits#
First, a major thanks to my friend sarat with whom I pair debugged a lot of the above issues and since he also runs a home server, he was my go-to person to ask doubts!
Here are some links that I collected while setting all of this up and might be useful as references if you’re planning a similar setup!
- How Tailscale Works
- What are these 100.x.y.z addresses?
- k3s config reference
- P2P across NAT
- Remembering the LAN
- Cloudskew (wonderful tool for creating architecture diagrams)
If you’ve any questions please find me on Twitter @mrkaran. You can find all of the setup on GitHub.
Till next time, if we survive the pandemic!