Kubernetes cluster on RPi
So, I got hold of 2 Raspberry Pi4 (still limited stocks in India) recently and wanted to build a Kubernetes cluster. Don’t ask why cause that would be pointless. I’ve little experience with a managed Kubernetes workload (Amazon EKS, which btw deserves its post 😝) but never really played around any of the K8s internal stuff yet. In this post, I’ll show you how I got a lightweight Kubernetes distro: K3s up and running.
k3s is a pretty great Kubernetes distro which passes the K8s Conformance tests. On ARM architectures, you’re pretty much resource-bounded and you want the resource footprint of your infra to be as minimal as possible. In k3s there are a few changes such as the persistent layer of K8s is replaced with SQLite instead of etcd, unusable (legacy/alpha) features of K8s are removed and cloud-provider plugins are not bundled (but can be installed separately). All of this together means just 40MB of a binary to run the cluster and ~250MB of memory usage on an idle cluster. Awesome, team Rancher :)
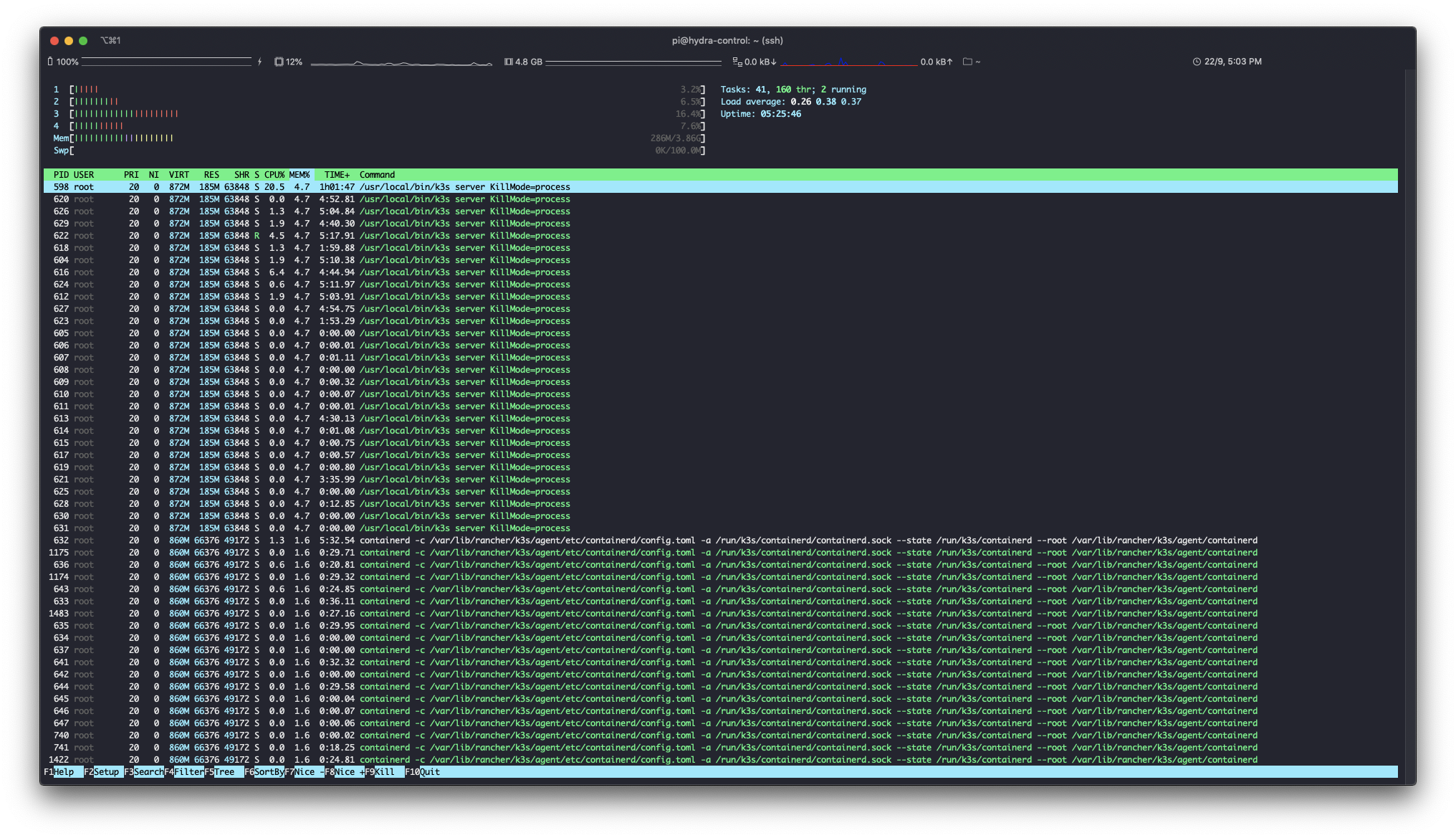
Automation is the key and even though I have just 2 nodes on RPi, I Ansible-ized the setup which I am hoping would save time in future if I add more nodes to the setup.
Hardware#
- 1x RPi4 4GB and 1x RPi4 2GB variant
- 2x Samsung EVO micro SD Card
- 2x USBC Cables
- 1x Amker Power Port (don’t compromise on the power supply, give enough juice so RPi doesn’t throttle)
- 1x TP-Link Network Switch (my router has only 1 usable LAN port)
- 2x CAT5 LAN cables (keeping it basic, you can get fancy flat LAN cables if you wish to)
This is how the final setup looks like:
{{< tweet 1175659256764219392 >}}
Setting up RPi#
I downloaded Raspbian Buster Lite because it’s the easiest to setup. Next step is to flash the SD card and for that, I used Etcher.
To enable SSH access, you need to create an empty file ssh in the root volume.
sudo touch /boot/sshOnce all sorted, we can use Ansible to set up the basic OS stuff, like changing the default password, enabling password-less SSH login, timezone & locale settings, changing hostname etc. I’ll be sharing relevant Ansible snippets, if interested you can check out the complete playbook at mr-karan/hydra repo.
We need to enable container features on the RPi so that containerd can run. Containers like Docker make use of cgroups (Linux kernel feature) which allows them to put resource limits on container processes like CPU and Memory. To enable cgroups, you need to edit /boot/cmdline.txt.
- name: Add cgroup directives to boot command line config
lineinfile:
path: /boot/cmdline.txt
regexp: '((.)+?)(\scgroup_\w+=\w+)*$'
line: '\1 cgroup_enable=cpuset cgroup_memory=1 cgroup_enable=memory'
backrefs: yesQuick Tip: If you’re going to use RPi as a headless server (not connecting with any monitor) you can reduce the GPU Memory to lowest possible (16M)
- name: Set GPU memory split to 16 MB
lineinfile:
path: /boot/config.txt
line: "gpu_mem=16"
create: yesDeploy K3s cluster#
Next, we’ll come to the actual stuff, where we’ll download K3s binary and run as a systemd service. There’s a handy shell script to bootstrap the cluster provided by the Rancher team which setups the whole thing in one command. But if you wanna learn/play around I’d recommend you do things the hard way (it’s not all that hard tho. ((twss!)).
- name: Download k3s binary armhf
get_url:
url: https://github.com/rancher/k3s/releases/download/{{ k3s_version }}/k3s-armhf
dest: /usr/local/bin/k3s
owner: root
group: root
mode: 755
when: ( ansible_facts.architecture is search("arm") )
and
( ansible_facts.userspace_bits == "32" )On the worker node, the process is similar, except you have to run the K3s with agent compared to server argument in the control plane. Things get a bit interesting here though. You need to give the cluster server URL along with it’s token in the command. A unique token is generated by the server at (/var/lib/rancher/k3s/server/node-token) which is used to join the worker nodes.
I did a bit of google-fu and got to know about this neat little Ansible module set_fact which lets you “store” a variable from one host and use it in a second host. Every Ansible host maintains a Python dict of “host facts”. In the second node, I access the cluster’s host fact dict, fetch the variable and use it in its systemd service template. Neat, ain’t it? Ansible has so many modules, it is mind-boggling.
Reading and storing the variable as a “host” fact:
# on the cluster
- name: Read node-token from control node
slurp:
src: /var/lib/rancher/k3s/server/node-token
register: node_token
- name: Store control node-token
set_fact:
k3s_cluster_token: "{{ node_token.content | b64decode | regex_replace('\n', '') }}"Using the variable from the server host, in a template on the agent host:
# on the agent (vars.yml)
k3s_server_address: "{{ hostvars[groups['control'][0]].k3s_server_address }}"
k3s_cluster_token: "{{ hostvars[groups['control'][0]].k3s_cluster_token }}"
# use the value in a template
...
[Service]
ExecStart=/usr/local/bin/k3s agent --server {{ k3s_server_address }} --token {{ k3s_cluster_token }}
...P.S. Shoutout to Ansible tho. It is one of my fav infra tooling available out there. It has some gotchas that you need to be aware of but by and large, the experience has been quite pleasant.
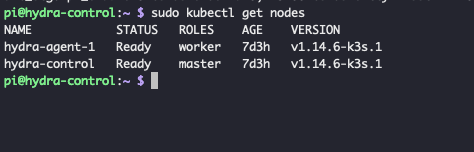
On the cluster, you should be able to see the nodes.

Team #SelfHost#
I am planning to host Bitwarden, Gitea and a Nextcloud instance on this cluster. Also will be using this as a testbed to play around with K8s internals. Stay tuned as I explore more of this!
Cheers! :)