Monitoring my home network
I like monitoring stuff. That’s what I do at work and when my home ISP started giving me random problems and I decided it would be nice to monitor my home network as well. There are a couple of ways to go around this, a very popular and OSS solution is SmokePing. SmokePing is written in Perl and is used to visualise network latencies. It’s quite a great solution but for my current stack which involves Prometheus and Grafana, it meant I had to deploy a standalone tool separate from my monitoring stack - something which I wanted to avoid.
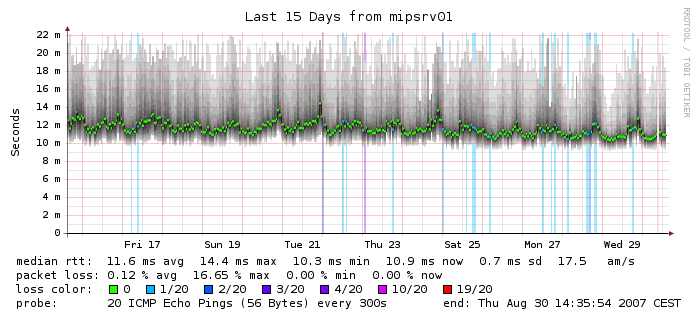
So, I looked for other solutions and luckily happened to stumble upon oddtazz in one of the common Telegram groups where he shared his solution for the above: Telegraf ICMP plugin and Grafana. This is exactly what I’ve been looking for but for some reason, I had wrongly assumed Telegraf needs InfluxDB to store the data. Googling a bit more, I found Telegraf supports Prometheus format (amongst a huge list of others!) but this wasn’t so clear in their docs.
I decided to run a Telegraf agent in my RPi connected to my home router over LAN and scrape metrics using Prometheus and visualise graphs in Grafana! For the non-patient readers, here’s what my dashboard looks like!:
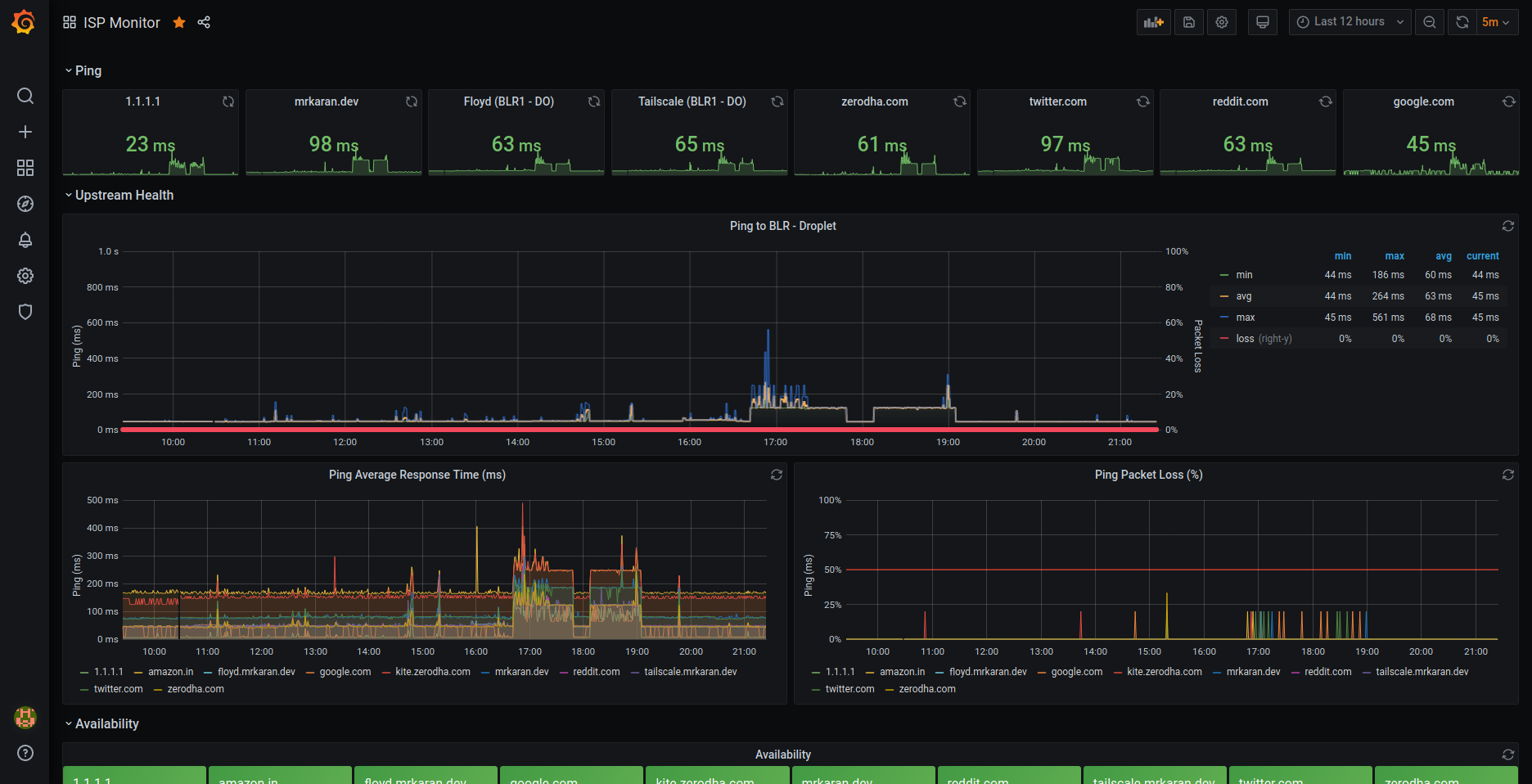
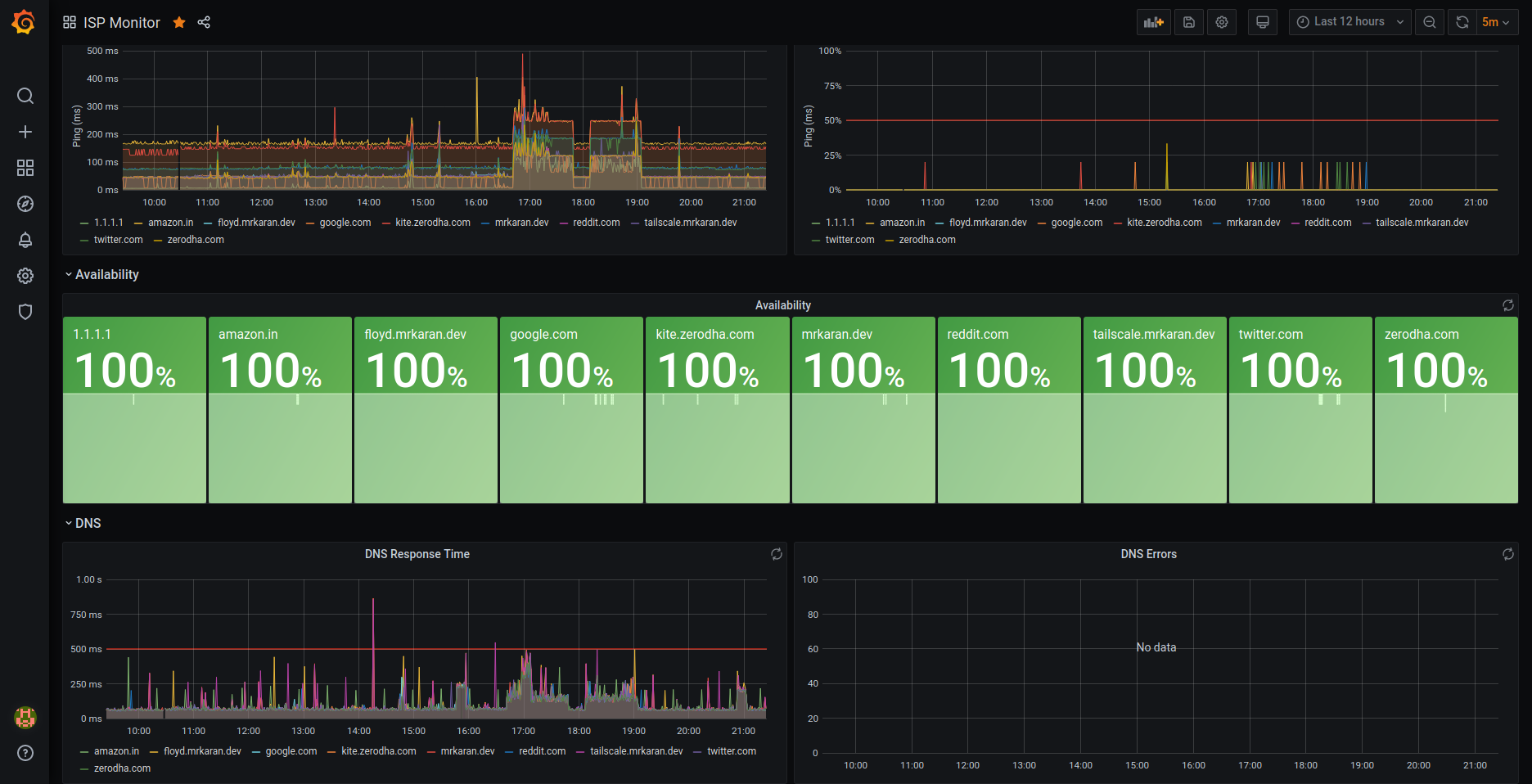
Setup#
To get started, we need to download Telegraf and configure the Ping plugin. Telegraf has the concept of Plugins for Input, Output, Aggregating and Processing. What this basically means is that you can configure multiple input plugins like DNS, ICMP, HTTP and export the data of these plugins in a format of your choice with Output plugins. This makes Telegraf extermely extensible, you could write a plugin (in Go) of your choice if you fancy that as well!
Here’s what my telegraf.conf looks like:
# Input plugins
# Ping plugin
[[inputs.ping]]
urls = ["mrkaran.dev", "tailscale.mrkaran.dev", "floyd.mrkaran.dev", "1.1.1.1", "kite.zerodha.com", "google.com", "reddit.com", "twitter.com", "amazon.in", "zerodha.com"]
count = 4
ping_interval = 1.0
timeout = 2.0
# DNS plugin
[[inputs.dns_query]]
servers = ["100.101.134.59"]
domains = ["mrkaran.dev", "tailscale.mrkaran.dev", "floyd.mrkaran.dev", "1.1.1.1", "kite.zerodha.com", "google.com", "reddit.com", "twitter.com", "amazon.in", "zerodha.com"]
# Output format plugins
[[outputs.prometheus_client]]
listen = ":9283"
metric_version = 2Firstly, so nice to see an Ops tool not using YAML. Kudos to Telegraf for that. I’d love to see other tools follow suit.
Getting back to the configuration part, input.plugin is a list of plugins that can be configured and I have configured the Ping and DNS plugin in my config. The output is in Prometheus format so it can be scraped and ingested by Prometheus’ time-series DB.
Running Telegraf#
With the above config in place, let’s try running the agent and see what metrics we get. I am using official Docker image to run the agent with the following config:
docker run --name telegraf-agent --restart always -d -p 9283:9283 -v $PWD/telegraf.conf:/etc/telegraf/telegraf.conf:ro telegrafAfter running the above command, you should be able to see the metrics at localhost:9283/metrics
$ curl localhost:9283/metrics | head
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
0 0 0 0 0 0 0 0 --:--:-- --:--:-- --:--:-- 0# HELP dns_query_query_time_ms Telegraf collected metric
# TYPE dns_query_query_time_ms untyped
dns_query_query_time_ms{dc="floyd",domain="amazon.in",host="work",rack="work",rcode="NOERROR",record_type="NS",result="success",server="100.101.134.59"} 124.096472
dns_query_query_time_ms{dc="floyd",domain="google.com",host="work",rack="work",rcode="NOERROR",record_type="NS",result="success",server="100.101.134.59"} 136.793673
dns_query_query_time_ms{dc="floyd",domain="kite.zerodha.com",host="work",rack="work",rcode="NOERROR",record_type="NS",result="success",server="100.101.134.59"} 122.780946
dns_query_query_time_ms{dc="floyd",domain="mrkaran.dev",host="work",rack="work",rcode="NOERROR",record_type="NS",result="success",server="100.101.134.59"} 137.915851
dns_query_query_time_ms{dc="floyd",domain="twitter.com",host="work",rack="work",rcode="NOERROR",record_type="NS",result="success",server="100.101.134.59"} 111.097483Perfect! Now, we’re all set to configure Prometheus to scrape the metrics from this target. In order to do that you need to add a new Job:
- job_name: "ispmonitor"
scrape_interval: 60s
static_configs:
- targets: ["100.94.241.54:9283"] # RPi telegraf AgentIn the above config, I am plugging my Tailscale IP assigned to my RPi on the port where Telegraf agent is bound to. This is one of the many reasons why Tailscale is so bloody awesome! I can connect different components in my network to each other without setting up any particular firewall rules, exposing ports on a case by case basis.
Sidenote: If you haven’t read Tailscale’s amazing NAT Traversal blog post, do yourself a favour and check it out after you finish reading this one ofcourse!
Anyway, coming back to our Prometheus setup, we can see the metrics being ingested:
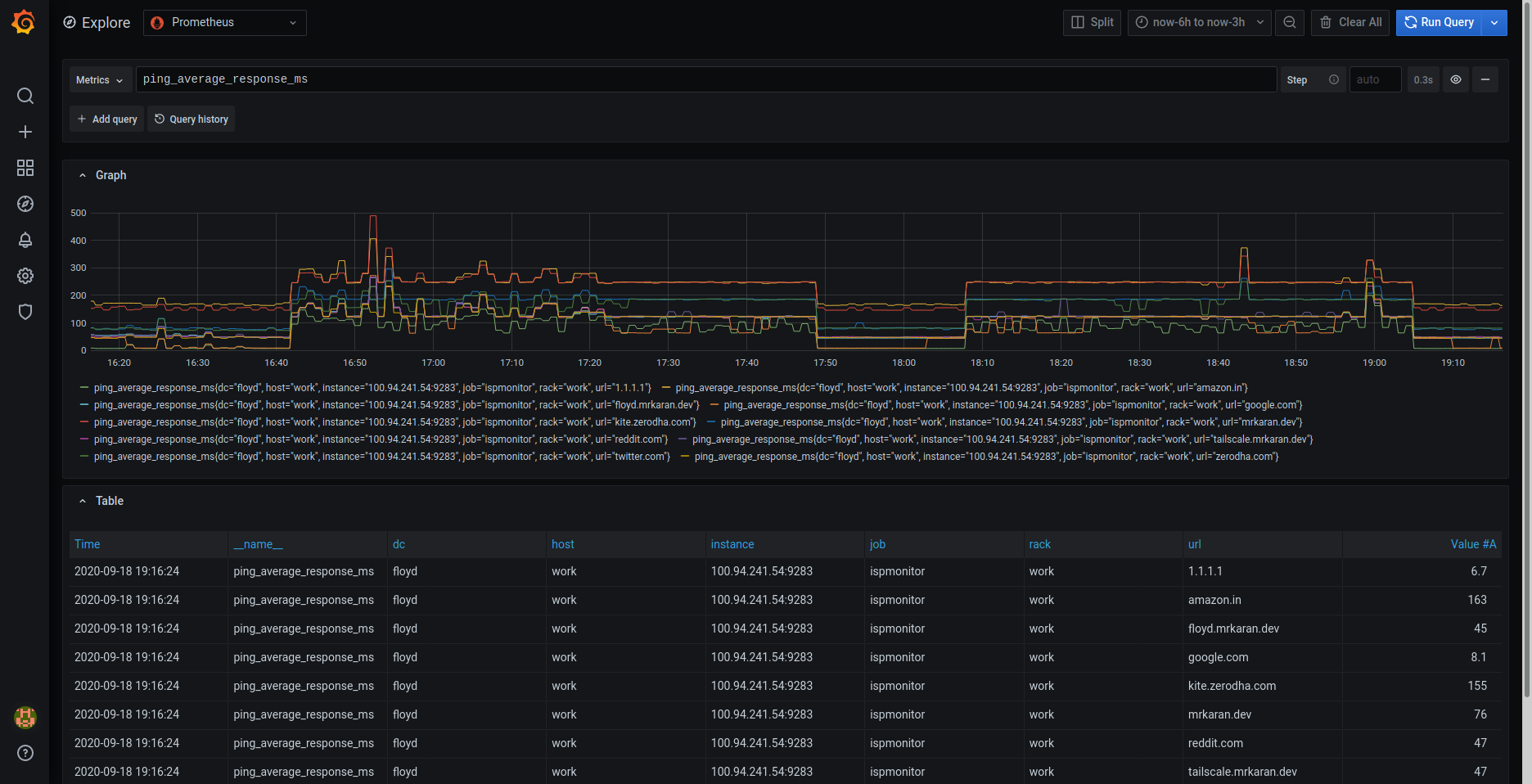
Show me the graphs#
Now comes the exciting bit – making pretty graphs. First, let’s discuss what’s the most important data I can extract out of Ping and DNS plugins. These plugins export decent amount of data, but a good rule of thumb while making dashboards is to optimise signal v/s noise ratio. We’ll do that by filtering out only the metrics that we care for.
Let’s checkout all the metrics exported by Ping plugin:
$ curl localhost:9283/metrics | grep ping | grep TYPE
# TYPE ping_average_response_ms untyped
# TYPE ping_maximum_response_ms untyped
# TYPE ping_minimum_response_ms untyped
# TYPE ping_packets_received untyped
# TYPE ping_packets_transmitted untyped
# TYPE ping_percent_packet_loss untyped
# TYPE ping_result_code untyped
# TYPE ping_standard_deviation_ms untyped
# TYPE ping_ttl untypedPerfect! So, from the above list of metrics, the most important ones for us are:
ping_average_response_ms: Avg RTT for a packetping_maximum_response_ms: Max RTT for a packetping_percent_packet_loss: % of packets lost on the way
With just the above 3 metrics, we can answer questions like:
- Is my ISP suffering an outage?
If yes, ping_percent_packet_loss should be unusually higher than normal. This usually happens when the ISP has routing is borked and that causes the packet to be routed in a less optimized way and as a side effect packet loss becomes one of the key metrics to measure here.
- Is the upstream down?
If yes, ping_average_response_ms over a recent window should be higher than a window compared to a previous time range when things were fine and dandy. This can either mean 2 things: Either your ISP isn’t routing correctly to the said upstream or the CDN/Region where your upstream is faced an outage. This is quite a handy metric for me to monitor!
How many times have your friends complained “xyz.com isn’t working for me” and when you try to load, it’s fine from your end? There are a lot of actors at play but ping is usually the most simple and quickest way to detect whether an issue persists or not. Of course, this doesn’t work for hosts which block ICMP packets altogether. They are not rare either, like netflix.com and github.com both block ICMP probes for example. For my use case, this wasn’t a major issue as I was able to still probe a decent amount of upstreams all over the world.
With that out of the way, let’s break the dashboard into different components and see what goes behind them.
Ping Response Panel#

To plot this, simply choose a Stat visualisation with the query ping_average_response_ms{url="$url"}. Repeat this panel for the variable $url and you should be able to generate a nice row view like this.
Additonally you can choose Thresholds and the Unit to be displayed in the panel with these options.
Ping Response Time Graph#
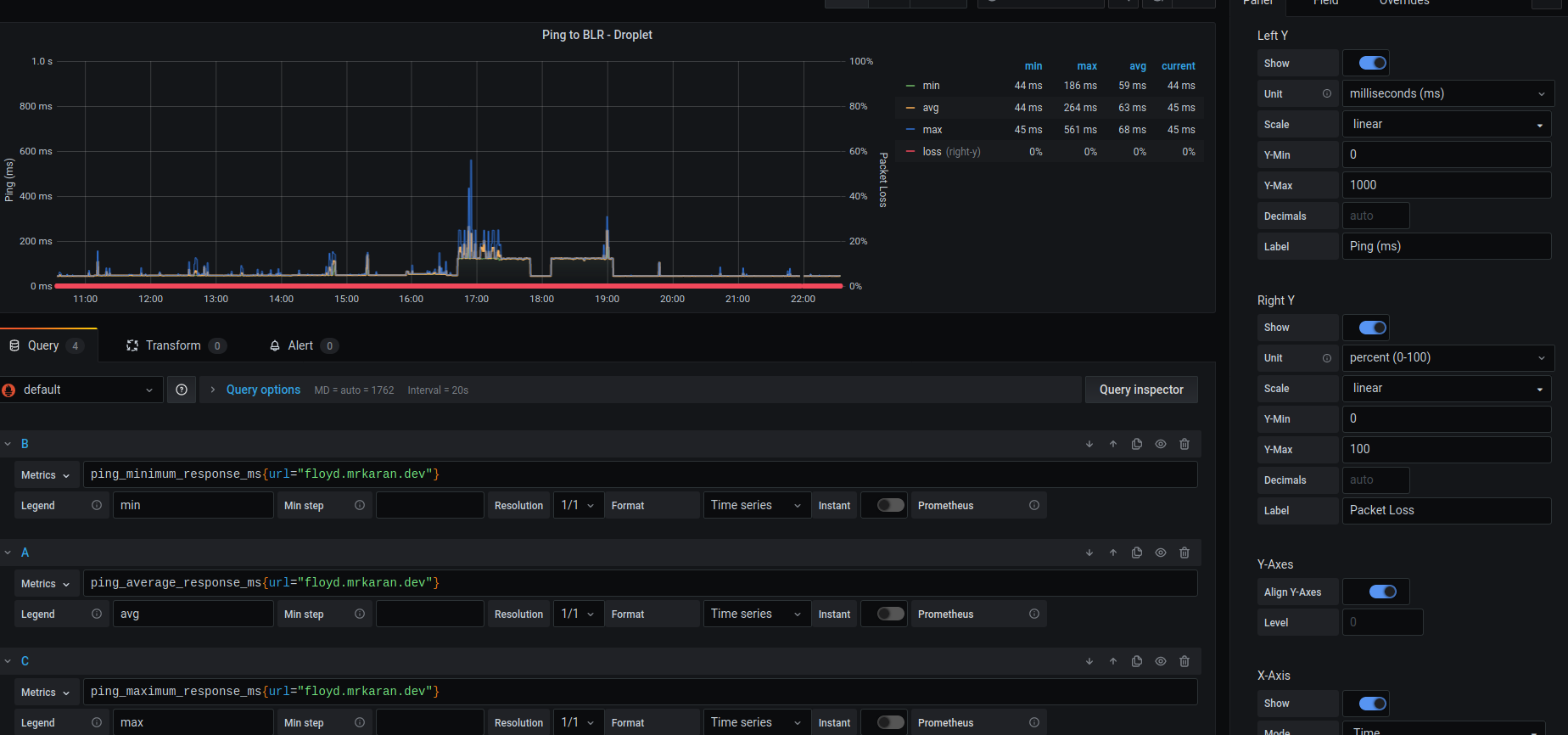
The next graph is interesting, it lets me visualise the avg, min, max ping response time as well as the % packet loss plotted on the Y2 (right Y) axis.
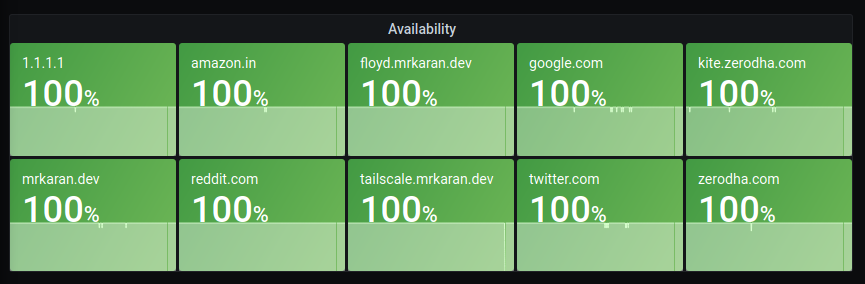
Availability Panel#
An interesting query to calculate uptime (just in the context whether the upstream is reachable) is:
100 - avg_over_time(ping_percent_packet_loss[2m])Since I scrape metrics at an interval of 1m(in order to not ping too frequently and disrupt my actual browsing experience), in this query I am averaging the data points for the metric ping_percent_packet_loss in a [2m] window.
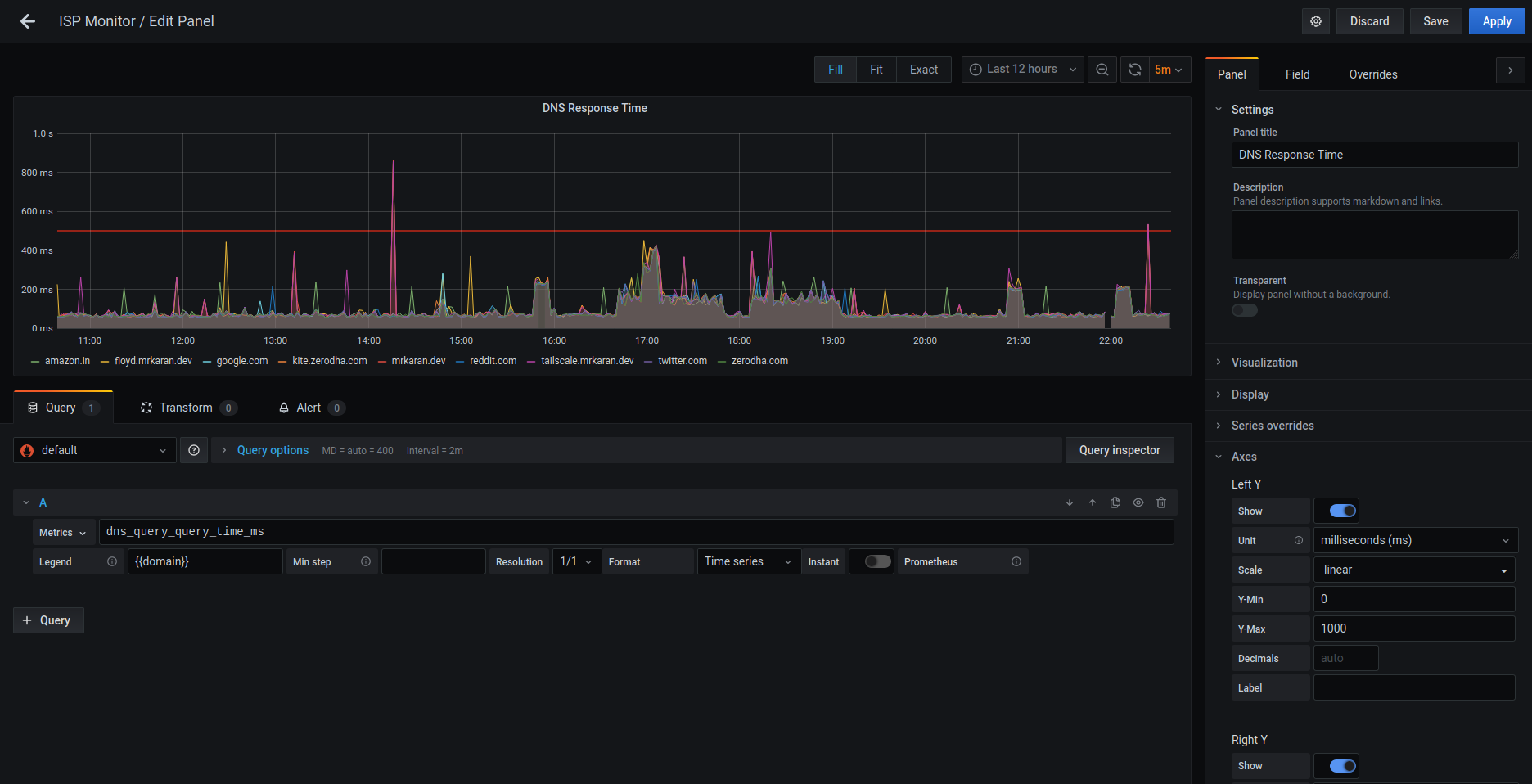
DNS Response Time Graph#
We can similarly query the DNS response time by visualising the average response time for a DNS query. This might be useful only to people self-hosting their DNS servers.
Conclusion#
So with a pretty simple and minimal OSS solution, I was able to setup monitoring for my home network! Over the last few days whenever my ISP had slightest of trouble, I can correlate it with my metrics! I mean I still can’t do anything about it cause the other person on ISP’s customer support is “Did you try rebooting your router” – the quintessential solution to all tech problems. Wish we could reboot this entire damn 2020 as well, but one could hope!
Shoot me for any questions on my Twitter @mrkaran_ :)
Fin!