Cleaning up Notes with LLM
My Obsidian vault has gotten quite messy over time. I’ve been dumping notes without proper frontmatter, tags were all over the place, and some notes didn’t even have proper titles! I needed a way to clean this up without spending hours manually organizing everything.
I’d been playing around with Claude’s API lately, and thought – hey, why not use an LLM to analyze my notes and add proper frontmatter? After all, that’s what these AI models are good at – understanding context and categorizing stuff.
I wrote a small Python script using the llm library (which is pretty neat btw) to do just this. Here’s what it looks like:
import llm
import os
import yaml
import datetime
from pathlib import Path
import re
class ObsidianNoteProcessor:
def __init__(self, notes_dir, model_name="claude-3.5-sonnet"):
self.notes_dir = Path(notes_dir)
self.model = llm.get_model(model_name)
def extract_existing_frontmatter(self, content):
"""Extract existing frontmatter if present."""
frontmatter_pattern = r'^---\n(.*?)\n---\n'
match = re.match(frontmatter_pattern, content, re.DOTALL)
if match:
try:
return yaml.safe_load(match.group(1)), content[match.end():]
except yaml.YAMLError:
return {}, content
return {}, content
def generate_prompt(self, content):
"""Generate a prompt for the LLM to analyze the note content."""
return f"""Analyze the following note content and extract/infer the following properties:
1. A clear title (if not present, generate from content)
2. Relevant categories based on the content
3. Appropriate tags (include 'inbox' if content seems draft-like)
4. Status (Draft/In Progress/Complete) based on content completeness
5. Priority (Low/Medium/High) based on content importance
6. A brief description summarizing the content
Note content:
{content}
Return ONLY the YAML frontmatter without any code block markers. Use this exact format (omit fields if not applicable):
title: <title>
category: <category>
tags:
- tag1
- tag2
status: <status>
priority: <priority>
description: <description>"""
def clean_llm_response(self, response_text):
"""Clean up the LLM response to ensure proper YAML."""
# Remove yaml code block markers if present
response_text = response_text.strip()
if response_text.startswith('```yaml'):
response_text = response_text.split('\n', 1)[1]
if response_text.endswith('```'):
response_text = response_text.rsplit('\n', 1)[0]
return response_text.strip()
def process_note(self, file_path):
"""Process a single note file."""
try:
with open(file_path, 'r', encoding='utf-8') as f:
content = f.read()
# Extract existing frontmatter and content
existing_frontmatter, main_content = self.extract_existing_frontmatter(content)
# Generate and execute prompt
response = self.model.prompt(self.generate_prompt(main_content))
response_text = self.clean_llm_response(response.text())
try:
new_frontmatter = yaml.safe_load(response_text)
if not isinstance(new_frontmatter, dict):
print(f"Warning: Invalid response format for {file_path.name}")
new_frontmatter = {}
except yaml.YAMLError as e:
print(f"YAML parsing error for {file_path.name}")
print(f"Response text was:\n{response_text}")
raise e
# Merge with existing frontmatter, preferring existing values
merged_frontmatter = {**new_frontmatter, **existing_frontmatter}
# Add date if not present
if 'date' not in merged_frontmatter:
merged_frontmatter['date'] = datetime.date.today().isoformat()
# Generate new note content
new_content = "---\n"
new_content += yaml.dump(merged_frontmatter, sort_keys=False, allow_unicode=True)
new_content += "---\n\n"
new_content += main_content.strip()
# Write back to file
with open(file_path, 'w', encoding='utf-8') as f:
f.write(new_content)
print(f"✓ Processed: {file_path.name}")
except Exception as e:
print(f"✗ Error processing {file_path.name}: {str(e)}")
def process_vault(self):
"""Process all markdown files in the vault."""
print("Starting Obsidian vault cleanup...")
for file_path in self.notes_dir.glob('**/*.md'):
self.process_note(file_path)
print("\nVault cleanup completed!")
def main():
# Set up the model key if not already configured
model = llm.get_model("claude-3.5-sonnet")
if not hasattr(model, 'key'):
api_key = os.getenv('ANTHROPIC_API_KEY')
if not api_key:
raise ValueError("Please set ANTHROPIC_API_KEY environment variable")
model.key = api_key
# Initialize and run the processor
notes_dir = "/Users/karan/Notes/Obsidian/The Wall/Notes"
processor = ObsidianNoteProcessor(notes_dir)
processor.process_vault()
if __name__ == "__main__":
main()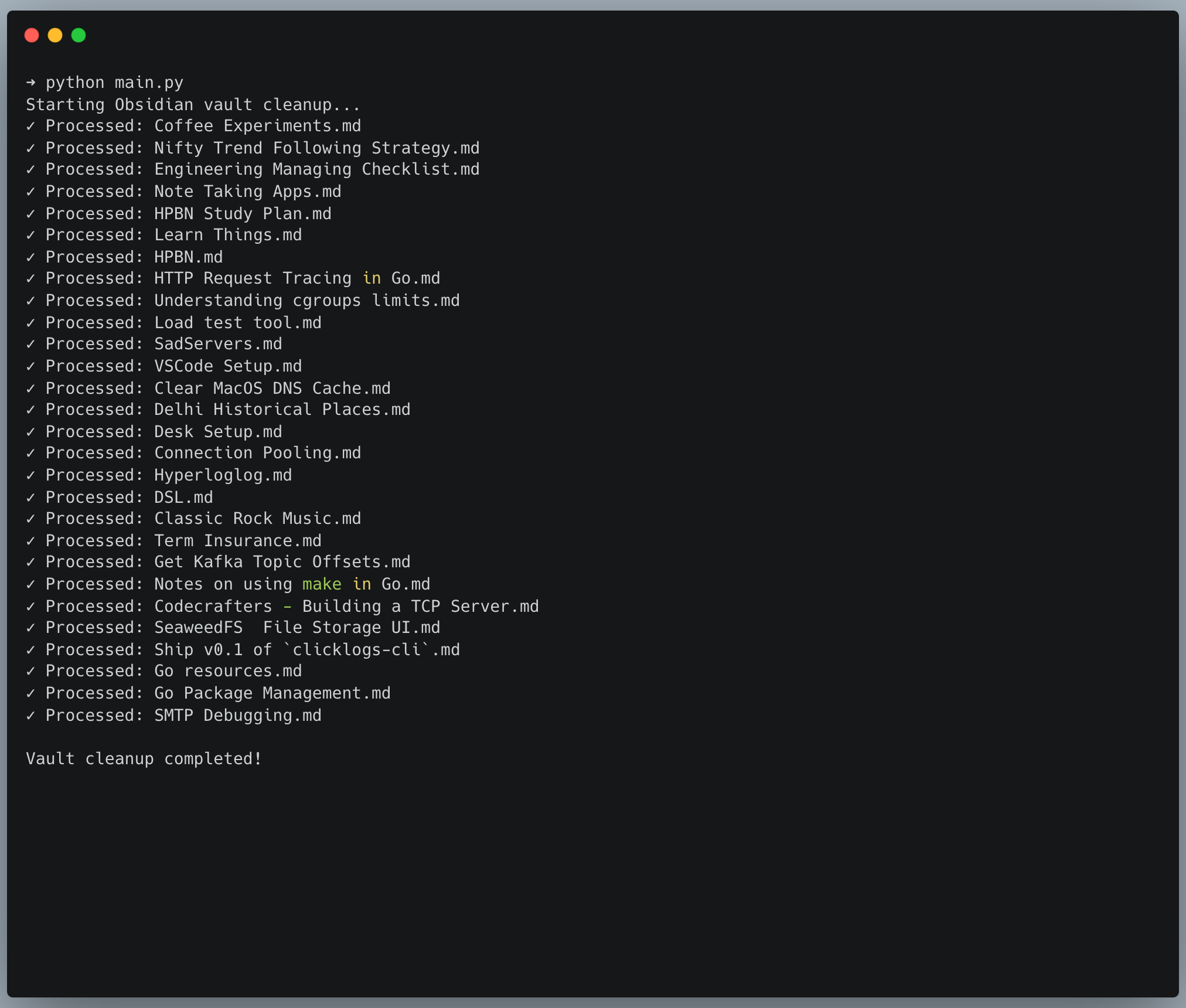
The script is pretty straightforward – it reads each markdown file, extracts any existing frontmatter (because I don’t want to lose that!), and then asks Claude to analyze the content and generate appropriate frontmatter. It adds stuff like title, category, tags, status, priority.
What I love about this approach is that it’s contextual. Unlike regex-based approaches or keyword matching, the LLM actually understands what the note is about and can categorize it properly. A note about “Setting up BTRFS on Arch” automatically gets tagged with “linux”, “filesystem”, “arch” without me having to maintain a predefined list of tags. The categorization is probably better than what I’d have done manually at 2 AM while organizing my notes!
Fin!